Alteration of the Sequence of Bases Revision Notes
Subject: Biology | Level: A-Level | Exam Board: AQA
Unlock top marks by mastering how a single change in a DNA base can have catastrophic effects on a protein's structure and function. This guide breaks down the complete causal chain, from mutation to non-functional enzyme, giving you the precise language and exam technique AQA rewards.
Revision Notes & Key Concepts
Key Terms & Definitions
- Gene Mutation
- A change in the sequence of nucleotide bases in a gene.
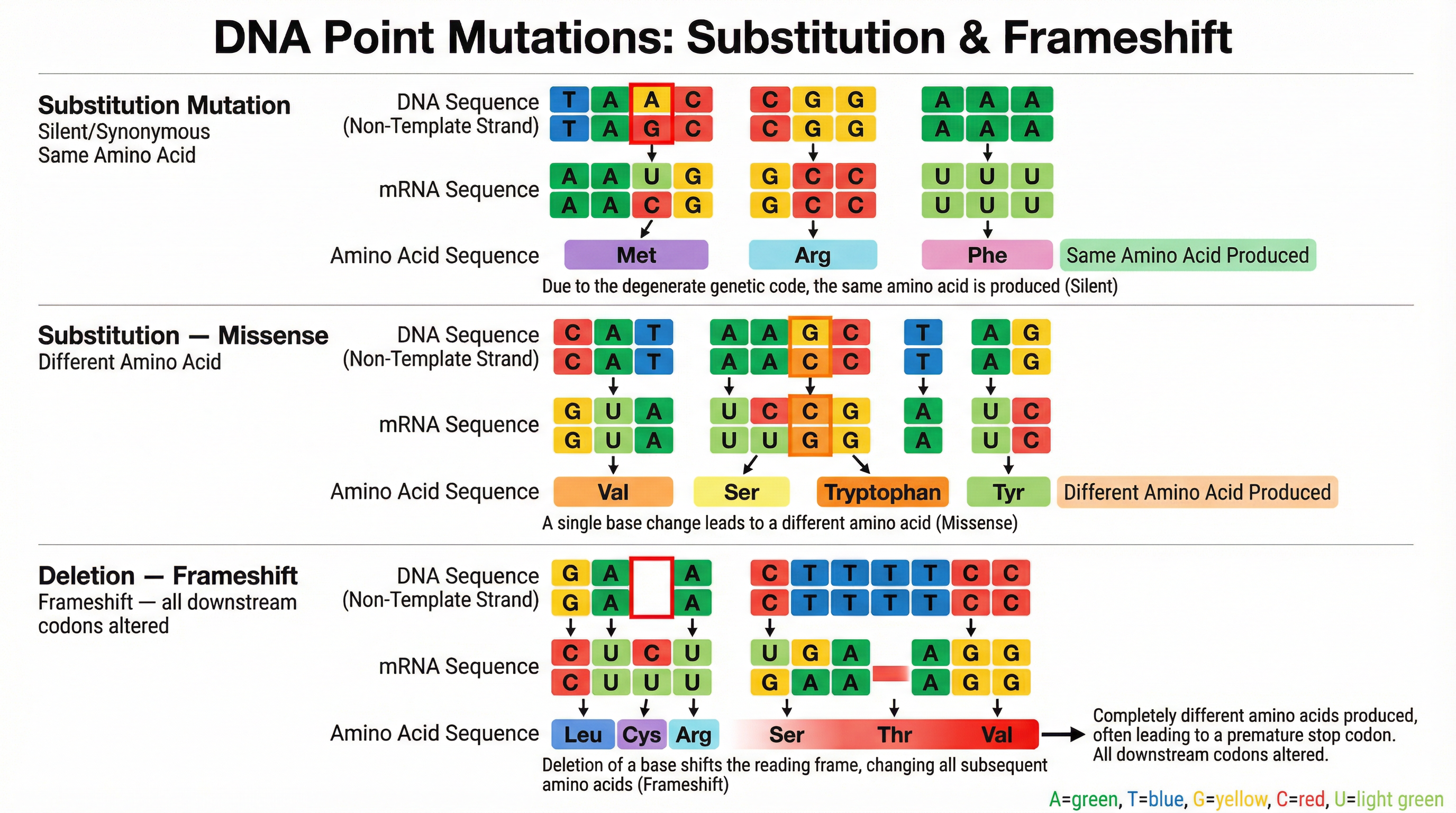
- Degenerate Code
- A feature of the genetic code where most amino acids are coded for by more than one codon.
- Frameshift Mutation
- A mutation caused by the addition or deletion of a number of bases that is not a multiple of three, which shifts the reading frame of the codons.
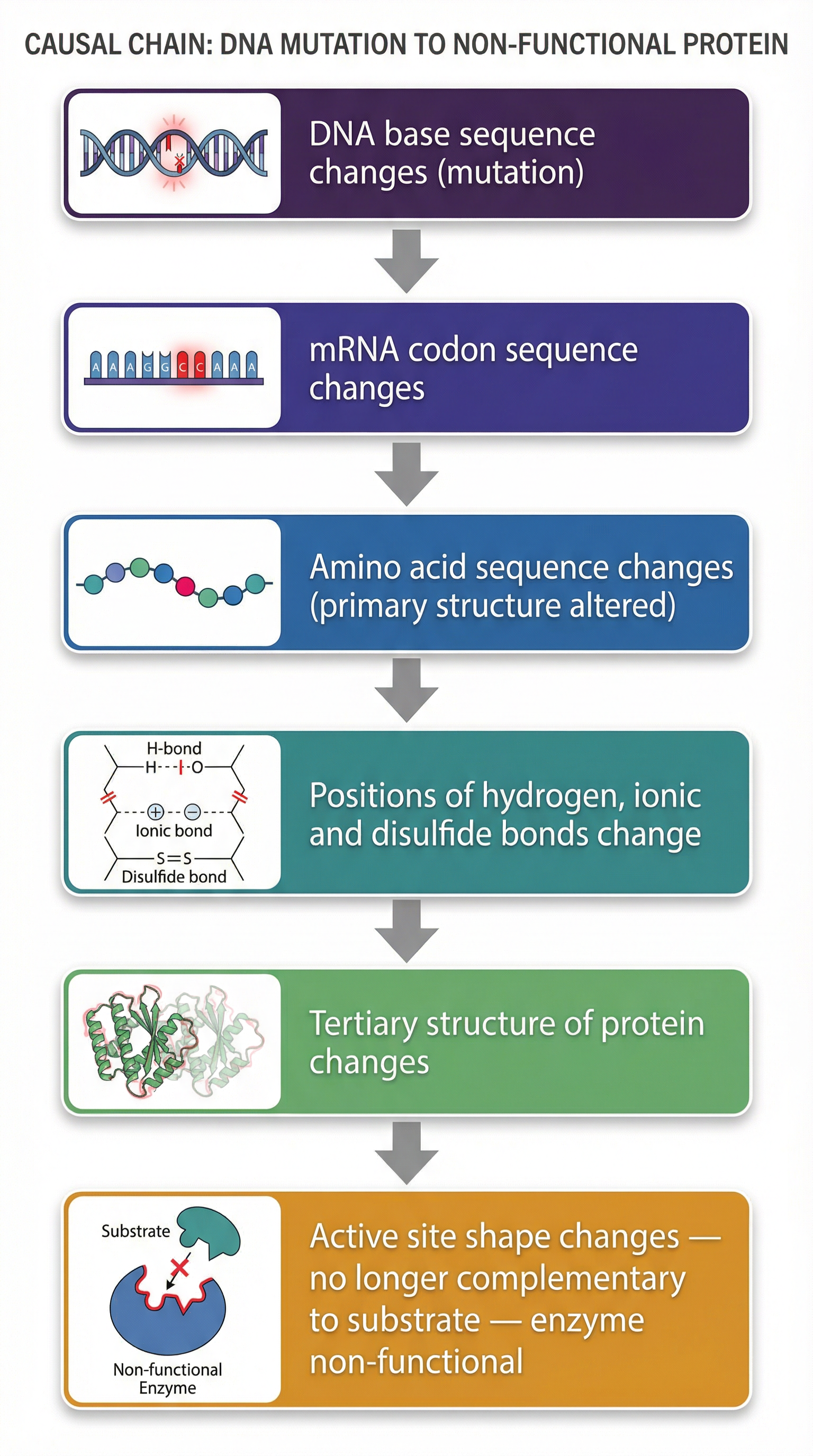
- Primary Structure
- The sequence of amino acids in a polypeptide chain.
- Tertiary Structure
- The final, three-dimensional shape of a protein, formed by the folding of the polypeptide chain and held in place by hydrogen, ionic, and disulfide bonds.
- Active Site
- A specific region on the surface of an enzyme to which a substrate molecule binds, and which has a shape complementary to the substrate.
Worked Examples
Worked Example
Question: Explain how a deletion mutation can lead to the production of a non-functional enzyme. (5 marks)
Solution: Step 1: State the immediate effect of the deletion. A deletion mutation involves the removal of one or more nucleotide bases from the DNA sequence. Step 2: Explain the frameshift. This causes a 'frameshift' because the genetic code is read in non-overlapping triplets. All subsequent triplets (codons) from the point of mutation are altered. Step 3: Link to primary structure. This changes the sequence of codons on the mRNA, leading to a different sequence of amino acids being coded for. The primary structure of the polypeptide is changed. Step 4: Link to tertiary structure. This results in a change in the position of hydrogen, ionic, and disulfide bonds that form between the amino acid R-groups. The polypeptide folds differently, altering the tertiary structure of the enzyme. Step 5: Explain the functional impact. The change in tertiary structure alters the shape of the enzyme's active site, so it is no longer complementary to the substrate. No enzyme-substrate complexes can form, and the enzyme is non-functional.
Worked Example
Question: A substitution mutation occurred in the middle of a gene. However, the protein produced was unchanged. Explain why. (3 marks)
Solution: Step 1: Define the mutation. A substitution mutation is the replacement of one DNA base with another. Step 2: Explain the genetic code. The genetic code is degenerate. This means that most amino acids are coded for by more than one DNA triplet/mRNA codon. Step 3: Conclude the outcome. The new triplet, resulting from the substitution, may code for the same amino acid as the original triplet. Therefore, the sequence of amino acids in the polypeptide remains unchanged, and the protein's structure and function are unaffected.
Worked Example
Question: Describe the differences between a gene mutation and a chromosome mutation. (4 marks)
Solution: Step 1: Define gene mutation. A gene mutation is a change in the nucleotide base sequence of a single gene, for example through substitution or deletion of bases. Step 2: Define chromosome mutation. A chromosome mutation involves a change in the structure or number of whole chromosomes. Step 3: Give an example of a chromosome mutation. An example is non-disjunction, where homologous chromosomes fail to separate during meiosis, leading to cells with one extra or one missing chromosome (aneuploidy), such as in Down's syndrome. Step 4: Contrast the scale of the mutations. Therefore, a gene mutation affects a single gene, while a chromosome mutation affects many genes, as it involves changes to large sections of DNA or entire chromosomes.
Practice Questions
Question: Explain why a deletion mutation is more likely to result in a change to an organism than a substitution mutation. (4 marks)
Answer:
Question: A mutation in the gene for the enzyme catalase occurs in an intron. Explain the effect this will have on the enzyme produced. (2 marks)
Answer:
Question: Explain how a single substitution mutation can cause sickle-cell anaemia. (6 marks)
Answer:
Question: Describe three ways that a mutation can be silent. (3 marks)
Answer:
Question: Explain why addition and deletion mutations are known as frameshift mutations. (2 marks)
Answer: